이전 글에서 홈에서 조회되는 추천 브랜드 목록에 대한 리팩토링을 진행할 때 로컬 캐시를 사용하였습니다. 이번글에서는 로컬 캐시에 대해 보다 자세하게 이야기를 해보려고 합니다.
왜 로컬 캐시냐
글로컬 캐시는 기본적으로 비용이 비쌉니다. 별도의 서버를 구축해야하고 이를 관리해야합니다. 하지만 저희 서비스는 초기이기 때문에 분산환경환경도 필요하지 않았습니다. 마지막으로 아직 캐시에 많은 데이터를 저장하지 않기 때문에 보다 가볍고 관리가 쉬운 로컬 캐시를 선택하였습니다.
로컬 캐시중에서 어떤걸 사용해야할까?
로컬캐시에는 몇가지 선택사항중 CaffeineCache를 선택하였습니다.
선택한 이유는 다음과 같습니다.
1. 성능이 압도적으로 좋다.



해당 이미지는 Caffeine Cache가 제공하는 벤치마킹 그래프입니다. Caffeine Cache가 제공하는것을 감안하더라도 동일/분산 key에서 Throughput , Write, Read 모든 부분에서 압도적으로 성능이 좋습니다.
2. 쓰기 편리하다
spring-boot-starter-cache 스타터에서 CaffeineCacheManager 가 autoConfig되어있습니다. JCache와도 호환됩니다.
3. time-based eviction을 지원합니다.
일정 기간후에 자동으로 캐시가 삭제되는것을 원하였는데 CaffeineCache는 timed-base eviction (= expiration) 정책을 제공합니다.
그중에서도 선택했던 가장 큰 이유인 성능에 대해서 이야기하려고합니다.
CaffeineCache는 왜 성능이 이렇게 차이날까?
최적의 적중률을 제공하는 Window TinyLfu 제거 정책 사용
이를 이해하기 위해 다음과 같은 Eviction 알고리즘(캐시가 가득 찼을 때 어떤 데이터를 제거할지 결정하는 캐시 관리 방법)에 대해 먼저 이해해야합니다. 여기서 살펴볼 알고리즘은 CaffeineCache와 관련있는 LRU/LFU만 알아보겠습니다.
LRU 알고리즘 (Least Recently Used Algorithm)
가장 오랫동안 사용되지 않은 캐시 항목을 제거하여 새로운 데이터를 저장하는 캐시 교체 알고리즘입니다.(페이지 교체 알고리즘으로도 많이 소개됩니다.)
LRU 동작 방식
- 데이터를 요청하면 캐시에 저장 (캐시 공간이 가득 차지 않았다면 그대로 저장)
- 이미 캐시에 있는 데이터를 요청하면 해당 데이터를 가장 최신 위치로 갱신
- 캐시가 가득 찼을 때 가장 오래 사용되지 않은 데이터를 제거
LRU 예제
- 캐시 크기: 3
- 요청 순서: [A, B, C, A, D]
- A 요청 → [A]
- B 요청 → [A, B]
- C 요청 → [A, B, C]
- A 요청 (A가 다시 사용됨) → [B, C, A]
- D 요청 (캐시 초과 → 가장 오래된 B 제거) → [C, A, D]
특징
- 시간 기반으로 데이터 교체
- 최근 사용된 데이터는 유지됨
- 사용 빈도가 아닌 시간 순서에 따라 캐시 데이터를 유지
이러한 LRU 알고리즘의 장점은 자주 사용하는 데이터를 우선 유지하여 성능 최적화할 수 있습니다.
LFU 알고리즘 (Least Recently Used Algorithm)
'최소 빈도 사용 알고리즘'으로 캐시 항목이 몇 번 사용되었는 지를 기준으로 가장 적게 사용된 캐시항목을 제거하여 새로운 데이터를 저장하는 캐시 교체 알고리즘입니다. 단순히 최근 사용한 것이 아닌 빈도를 기준으로 계산하기 때문에 접근 횟수(빈도)를 표시하는 데 추가 공간이 필요하므로 그만큼 메모리가 낭비됩니다.
LFU 알고리즘 동작 방식
- 데이터를 요청하면 캐시에 저장하고 사용 횟수를 기록
- 이미 캐시에 있는 데이터를 요청하면 해당 데이터의 사용 횟수 증가
- 캐시가 가득 찼을 때 가장 적게 사용된 데이터를 제거
LFU 예제
- 캐시 크기: 3
- 요청 순서: [A, B, C, A, D]
- A 요청 → [A(1)]
- B 요청 → [A(1), B(1)]
- C 요청 → [A(1), B(1), C(1)]
- A 요청 (A 사용 횟수 증가) → [A(2), B(1), C(1)]
- D 요청 (캐시 초과 → 가장 적게 사용된 B 또는 C 제거, 여기서는 B 제거) → [A(2), C(1), D(1)]
3. LRU vs LFU 비교
| 비교 항목 | LRU (Least Recently Used) | LFU (Least Frequently Used) |
| 기준 | 최근 사용 여부 | 사용 횟수 |
| 장점 | 최신 데이터 유지, 단순 구현 | 자주 사용되는 데이터 유지 |
| 단점 | 자주 사용하는 데이터도 오래 사용 안 하면 제거됨 | 오랫동안 사용된 데이터가 유지될 가능성 있음 |
| 사용 예시 | 웹 브라우저 캐시, 운영체제 페이지 교체 알고리즘 | 뉴스 피드 추천 시스템, AI 모델의 데이터 캐싱 |
CaffeineCache의 eviction 동작 원리
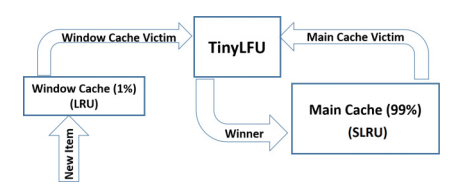

Main Cache (전체 용량 99%)
- Probation Cache(공간 80%)-자주 사용하는 데이터(제거 시 LRU rule 적용)
- Protected Cache(공간 20%)-자주 사용하지 않는 데이터 (제거되지 않음)
Window Cache (전체 용량 1%)
- 새로운 데이터가 Cache에 쓰일 때 가장 먼저 Window Cache에 쓰임
- 공간에 가득 찰 경우 LRU 식으로 Window Cache 밖으로 제거 (LRU)
- — Tiny LFU 알고리즘에 의해 제거되거나 Probation Cache 영역에 저장됨
- Probation 영역 데이터에 일정한 횟수 이상 접근되면 Protected Cache 역으로 승격됨
- — Protected Cache 영역이 Full 될 경우 오래된 데이터 밖으로 옮겨짐
- — — TinyLFU 알고리즘에 의해 제거되거나 Probation Cache 영역에 저장됨
- Window Cache / Protected Cache로부터 제거되는 데이터 = Candidate
- Probation Cache에서 제거되는 데이터 = Victim
- Candidate Cache 접근 > Victim Cache 접근 : Victim 데이터 제거
- Candidate Cache 접근 < Victim Cache 접근 && Candidate 접근 횟수 5번 이하 : Candidate 데이터 제거
- 둘 중 하나 랜덤하게 제거
Caffeine 캐시 내부 알고리즘은 LFU와 LRU의 장점을 통합
- 서로 다른 캐시 영역에 다른 특성을 가진 캐시 항목을 저장하여 최근에 생성된 캐시 데이터가 Window Cache로 들어가 삭제되지 않음
- 자주 호출되는 데이터 (LFU)은 Protected 영역에 들어가며 LRU에 의해 제거되지 않음
- 호출 횟수 / 호출 시간 두 개의 자원에 대해 밸런스가 잘 되어 있음
- — 자주 호출되고 최근에 생성된 데이터 들은 가능한 캐시에 유지 시킬수 있음
- 전통적인 LRU/LFU 로 처리 할 수 없던 케이스를 보다 잘 처리함
처음부터 바로 이해되지는 않았지만 차근차근 흐름을 따라가다 보니 이해되었습니다. 천천히 읽어보시길 추천드립니다.
이런 방식으로 최적의 적중률을 제공하는 Window Tiny LFU 제거 정책을 사용해서 가장 높은 성능을 보이고 있습니다.
주의할점
앞서 저는 time-based eviction을 사용한다고 말씀드렸습니다. 예를들어 24시간이라고 캐시의 유효시간을 설정해두면 24시간이되면 그 이후에는 expire 되어야합니다. 하지만 Caffeine Cache는 실제로 바로 expire되지 않습니다.
정해진 시간이 지나면 캐시는 만료되어 더 이상 참조할 수 없으나 메모리는 그대로 점유하고 있는 상태가 됩니다.
공식 문서에 따르면, 캐시 처리량이 높을 경우 (high-throughput) 굳이 만료된 캐시를 즉시 정리할 필요가 없다고 말하고 있습니다. 처리량이 높다면 캐시 데이터의 읽기/쓰기 작업이 빈번하게 발생하는 것이니 굳이 clean up 처리를 해주지 않아도 자연스럽게 오래된 캐시가 정리되기 때문입니다. 그렇기 때문에바로 삭제하지 않지만 실제로 캐시가 거의 사용되지 않는다면 불필요한 메모리 점유가 지속되니, 메모리 개선이 필요하다면 만료 후 즉시 제거되도록 설정해야 합니다.
Cache.cleanUp()을 이용해 외부스레드에서 명시적으로 캐시를 제거할 수도 있으나, 이 경우 TTL을 위해 직접 스케줄링 코드를 구현해야 하므로 비효율적이다. 카페인 개발자는 만료된 항목을 즉시 제거하고 싶다면 캐시를 설정할 때 scheduler 옵션을 추가할 것을 권장한다고 이야기 하고 있습니다.
마무리
이번글에서는 왜 Caffeine Cache라이브러리를 사용했는지 그 이유와 성능이 다른 캐시 라이브러리에 비해 월등히 좋은 이유인 Tiny LFU에 대해 살펴보았습니다. 그밖에 Caffeine Cache라이브러리는 다양한 옵션을 제공해주고 있으니 궁금하시다면 공식문서를 살펴보시는걸 추천드립니다.
https://docs.spring.io/spring-boot/reference/io/caching.html
Caching :: Spring Boot
The Spring Framework provides support for transparently adding caching to an application. At its core, the abstraction applies caching to methods, thus reducing the number of executions based on the information available in the cache. The caching logic is
docs.spring.io
https://github.com/ben-manes/caffeine?tab=readme-ov-file
GitHub - ben-manes/caffeine: A high performance caching library for Java
A high performance caching library for Java. Contribute to ben-manes/caffeine development by creating an account on GitHub.
github.com
참고
'개발 > 서버' 카테고리의 다른 글
| [ 프차연구소 ] graceful shutdown 설정하기 (1) | 2026.01.25 |
|---|---|
| [ 프차연구소 ] blue-green 무중단 배포 적용 (0) | 2026.01.24 |
| [프차천국] Spring Cache + JPA Lazy 로딩 조합에서 발생한 동시성 문제 해결하기( with Thundering Herd) (5) | 2025.11.25 |
| [프차천국] 랜덤 프랜차이즈 추천 API 3.7초 → 37ms까지 줄이기(후보 풀 캐싱 + Batch IN + Hibernate Batch Fetch) (2) | 2025.11.25 |
| DTO를 구현할 때 Record로 정의해야 할까, 클래스로 정의해야할까? (0) | 2025.10.24 |




댓글