

테스트 환경
1초에 100개의 요청을 전송. 3분동안 진행
쓰레드 수 : 1000
Ramp-up 시간 : 1s
지속시간 : 180s
상수 처리량 : 6000
전체 데이터 분석
평균 TPS가 1도 잘 안나오고,1분간 insert가 17274로 db 부하도 상당한것을 볼수있습니다. 다양한 알림들이 존재하고 저희 서비스에 알림은 핵심이기 때문에 이를 최적화 하여야만 합니다.
Batch insert를 사용하자.
// 알림을 저장한다.
List<Notification> notificationList = new ArrayList<>();
for(String receiverTrackingId : command.getReceiverTrackingIds()) {
Notification notification = Notification.from(command, receiverTrackingId, content);
notificationList.add(notification);
}
notificationRepository.saveAll(notificationList);
알림을 저장할때 saveAll을 사용하여 모든 알림을 저장하였습니다.

문제는 여러명에게 동시에 보내는 알림이 많았습니다. 예를들어 모임에 새로운 인원이 신청했을때 해당 모임의 관리자들에게 모두 알림이 가도록 하였는데 이때 알림 한건만으로도 상당히 많은 insert문이 생성되었습니다.

구현체를 살펴보니 반복문으로 구현되어있었습니다. 쿼리를 몰아서 보내지 않고 하나씩 가고있었습니다.
이를 개선하기 위해
이러한 insert 성능을 개선하기위해 Batch연산을 진행하여 Insert 쿼리를 하나로 묶어서 보내고자하였습니다.
배치 Insert란?
Batch Insert는 많은 양의 데이터를 한 번에 삽입하는 방법입니다. 아래의 일반적인 Insert SQL과 비교해 보면 이해하기 쉽습니다.
INSERT INTO table (col1, col2) VALUES (val1, val11);
INSERT INTO table (col1, col2) VALUES (val2, val22);
INSERT INTO table (col1, col2) VALUES (val3, val33);위 커리는 개별 insert이지만
INSERT INTO table (col1, col2) VALUES
(val1, val11),
(val2, val22),
(val3, val33);위 쿼리는 Batch Insert입니다.
보통 쿼리를 실행하고 응답을 받은 후에야 다음 쿼리를 전달하기 때문에 개별 Insert의 경우 지연 시간이 늘어나지만, 하나의 트랜잭션으로 묶이는 Batch Insert는 하나의 쿼리문으로 여러 데이터를 처리하기 때문에 성능이 뛰어납니다.

그러면 무조건 Batch Insert를 사용하면 되는거 아닌가?
하지만 JPA는 기본적으로 Batch Insert를 지원하지 않습니다. ID 생성 전략을 IDENTITY로 많이 사용하는데, 이렇게 되면JPA 사상과 맞지 않기 때문입니다.
IDENTIFY로 하면 왜?
@Entity
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Example {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
}
JPA와 MySQL을 함께 사용할 때, 위와 같이 IDENTITY 전략을 사용하여 auto_increment를 통해 PK 값을 자동으로 증가시키는 방식을 일반적으로 사용합니다. 이 방식은 jpa에서 id값을 명시하지 않아도 자동으로 저장합니다.
그러나 이 방식을 사용하면 Hibernate는 JDBC 수준에서 Batch Insert를 비활성화합니다.
이유는 새로 할당할 Key 값을 미리 알 수 없는 IDENTITY 전략을 사용할 경우, Hibernate가 채택한 flush 방식인 'Transactional Write Behind'와 충돌이 발생하기 때문입니다. 따라서 IDENTITY 전략을 사용하면 Batch Insert는 동작하지 않습니다.
이를 구체적인 예로 설명하면, OneToMany의 Entity를 insert할 경우 Hibernate는 아래 과정을 진행하며 이 과정의 쿼리를 모아서 실행합니다.
- 부모 Entity를 insert하고 생성된 Id를 반환
- 자식 Entity에서는 이전에 생성된 부모 Id를 FK 값으로 채워서 insert
하지만 Batch Insert와 같은 대량 등록의 경우, 이 방식을 사용할 수 없는데 부모 Entity를 한 번에 대량으로 등록하게 되면 어느 자식 Entity가 어느 부모 Entity에 매핑되어야 하는지 알 수 없습니다. 따라서 IDENTITY 전략을 사용하면 Batch Insert는 동작하지 않습니다.
물론 Auto Increment가 아닐 경우엔 아래와 같은 옵션을 통해 values 사이즈를 조절하여 Batch Insert를 사용할 수 있습니다.
spring.jpa.properties.hibernate.jdbc.batch_size=개수
JDBC Tempalte을 활용해서 Batch Insert를 적용하자.
테이블 전략을 변경하는 방법이 있지만, 이는 테이블 변경이 필요하고 이미 모든 서비스에서 진행 중이기 때문에 적용하기 어렵습니다. 그래서 대안으로 JdbcTemplate를 사용하여 Batch Insert를 적용하였습니다.
datasource:
url: ${NOTIFICATION_DB_URL}?rewriteBatchedStatements=truemysql url 설정에서 rewriteBatchedStatement를 true로 설정하였습니다.
@Override
public void saveAll(List<Notification> notificationList) {
String sql = "INSERT INTO p_notification ("
+ "tracking_id, notification_type, access_tracking_id, receiver_tracking_id, content, is_read, "
+ "created_at, created_by, modified_at, modified_by) " +
"VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)";
jdbcTemplate.batchUpdate(sql,
new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
Notification notification = notificationList.get(i);
UUID trackingId = UUID.randomUUID();
LocalDateTime createdAt = LocalDateTime.now();
LocalDateTime modifiedAt = LocalDateTime.now();
ps.setString(1, trackingId.toString());
ps.setString(2, notification.getNotificationType().name());
ps.setString(3, notification.getAccessTrackingId().toString());
ps.setString(4, notification.getReceiverTrackingId().toString());
ps.setString(5, notification.getContent());
ps.setBoolean(6, false); // 읽지 않음
ps.setTimestamp(7, Timestamp.valueOf(createdAt));
ps.setString(8, "System"); // 생성자
ps.setTimestamp(9, Timestamp.valueOf(modifiedAt));
ps.setString(10, "System"); // 수정자
}
@Override
public int getBatchSize() {
return notificationList.size();
}
}
);
}
기존에는 jpa의 saveAll로 저장하였지만 별도로 batchInsert를 구현하였습니다.
실행 비교
( insert 200개)
쿼리실행시간 비교.
batch Insert : 평균 32ms
jpa saveAll : 평균 321ms
200명에게 알림을 보내는것 만으로 10배의 속도 차이가 발생했습니다.
tps 비교 : 0.6~1.2사이였던 반면, 계속해서 최대 25를 유지하여 처리후 처리할 데이터가 줄어들면서 점차 감소합니다. 0.9 -> 25는 25배 향상. 처리시간도 원래는 최소 800이였는데 현재는 40. 20배 향상되었습니다.


벌크 연산을 사용할 경우 주의사항
※ 벌크 연산은 영속성 컨텍스트를 무시하고 DB에 직접 쿼리 한다는 점을 주의해야 한다.
즉, DB에 반영된 변경이 영속성 컨텍스트에는 반영되지 않는다는 말이다.
해결 방법
- em.refresh() 사용
- 벌크 연산 수행 직후 정확한 salary 엔티티를 사용해야 한다면, em.refresh(salary)를 사용하여 DB에서 salary를 다시 조회한다.
- 벌크 연산 먼저 실행
- 벌크 연산 먼저 실행하고 조회하면 된다. 가장 실용적인 해결책이며, JPA와 JDBC를 함께 사용할 때도 유용하다.
- 벌크 연산 수행 후 영속성 컨텍스트 초기화
- 영속성 컨텍스트에 남아 있는 엔티티를 제거하는 방법이다.

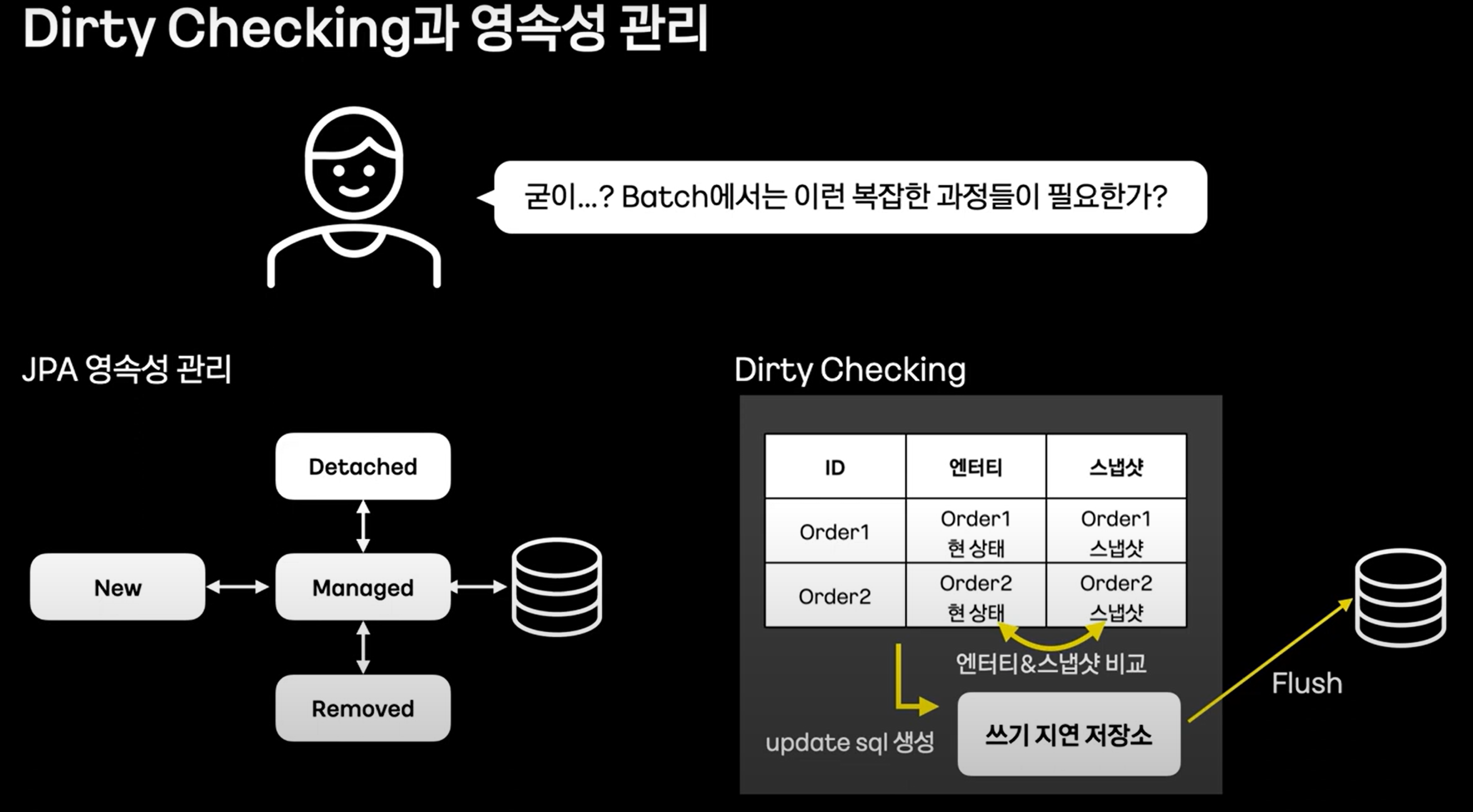
BATCH에서는 명확하게 읽는 부분과 쓰는 부분이 구분되어있습니다. 이런상황에서 영속성 컨텍스트와 더티체킹을 할필요없습니다.
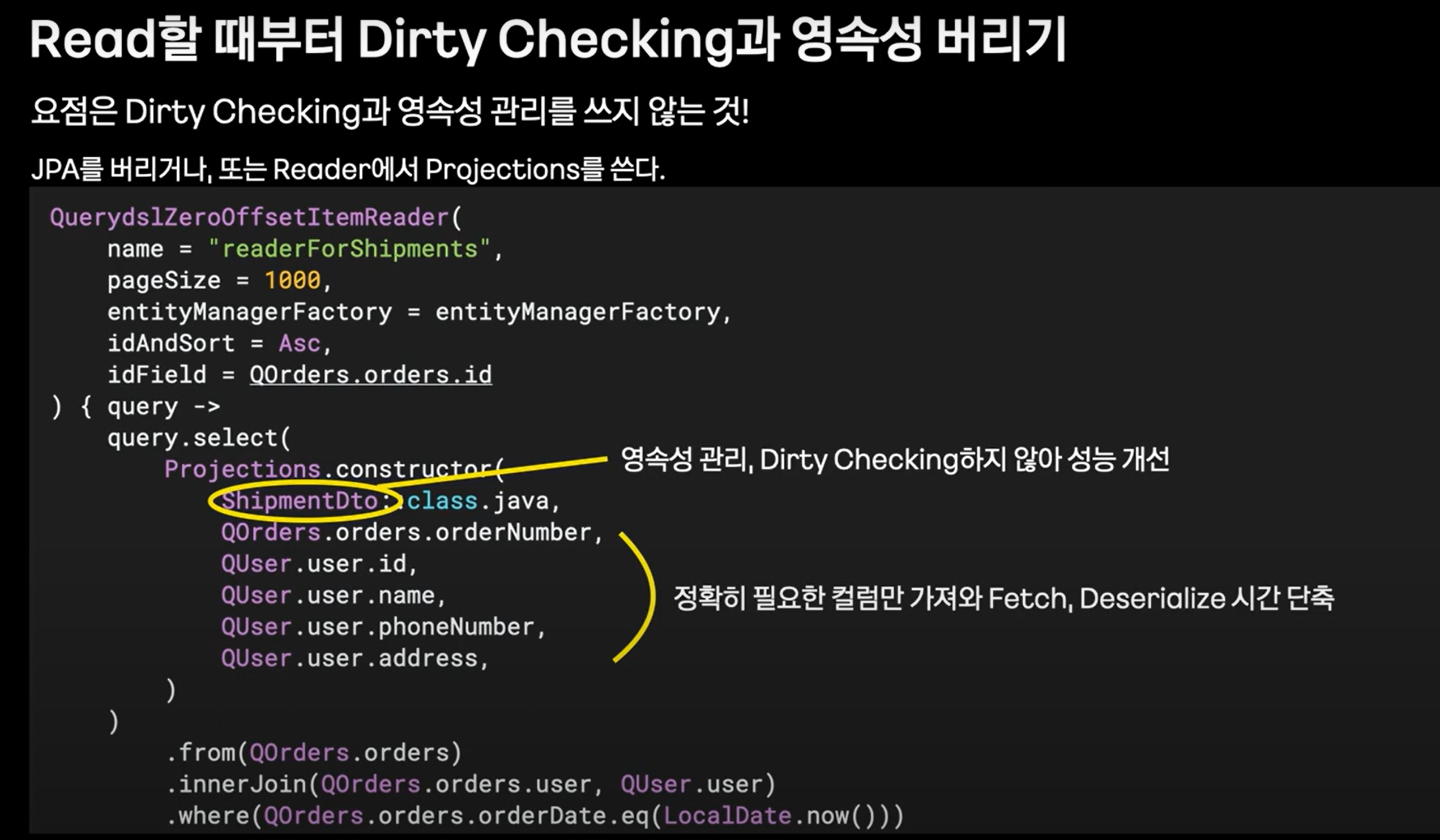

writer에서 jpa포기하고 batch insert 진행합니다.
성능 비교

파라미터를 setString, setLong으로 넣습니다. 그리고 executeBatch()하면 두 쿼리가 한번에 나갑니다.
마무리
이번에는 Batch Insert를 통해서 알림 쓰기 성능을 향상 시켰습니다. 하지만 여전히 DB부하가 상당하므로 추가적인 방안을 모색해 봐야할것 같습니다.




댓글